Informer avec des données structurées
Cet essai est la base de ma présentation à l’école d’été de l’INRIA qui se tient à Marseille du 18 au 22 septembre 2016.
Depuis la fin des années 2000, le terme de datajournalisme a émergé. Certains médias ont mis en place des équipes de datajournalisme. Des agences spécialisées se sont créées, comme celle que j’ai cofondé en 2011, Journalism++. De nombreuses écoles de journalisme offrent des cours de datajournalisme. Des conférences spécialisées ont lieu tous les ans. Si le concept a montré qu’il était plus qu’un buzzword ou qu’une mode, il reste mal défini. Certains y voient une “mythologie du chiffre”1. D’autres affirment que le datajournalisme consiste à “s’adresser à l’intelligence visuelle” de son audience2. Ces raccourcis passent à côté de l’essentiel. Faire du datajournalisme, c’est informer avec des données structurées. C’est l’utilisation de techniques statistiques, de visualisations et d’interactivité pour analyser et communiquer des données3.
Cet essai explique ce que le concept de datajournalisme recouvre, comment il est apparu et comment il influence le quotidien des rédactions. Surtout, il montre comment le datajournalisme s’intègre dans les processus d’information pré-existant et l’impact social de cette manière d’informer.
Les données structurées
Le concept de données vient du latin datum et désigne un élément utilisé dans une argumentation. Il s’oppose ainsi à un fait (factum), qui est, lui, le résultat de l’argumentation4. Cette distinction permet de comprendre qu’une donnée ne peut être réfutée, elle est, simplement.
Une donnée peut représenter n’importe quelle observation, quel que soit le format. En ce sens, toute production d’information se fonde sur des données, qui sont interprétées pour produire des faits. Lorsque l’on parle de journalisme de données, on évoque implicitement le concept de données structurées. On parle de données structurées lorsque les points de données suivent un même modèle. Chaque élément d’information est une instance d’un modèle abstrait et général. Le plus souvent, la structuration se fait dans un tableau, où chaque ligne représente une instance et chaque colonne représente une dimension du problème observé.
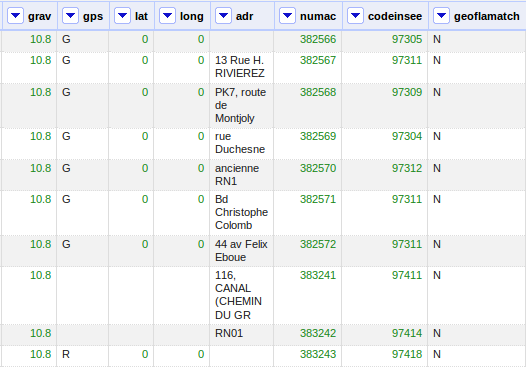 Un exemple de jeu de données structurées: Chaque ligne représente un accident de circulation, chaque colonne mesure une dimension (adresse, gravité, latitude, longitude etc.) de l’accident.
Un exemple de jeu de données structurées: Chaque ligne représente un accident de circulation, chaque colonne mesure une dimension (adresse, gravité, latitude, longitude etc.) de l’accident.
Il convient ici de rappeler que les données en elles-mêmes ne suffisent jamais à interpréter correctement une situation. Sans analyser en profondeur les relations de pouvoir autour d’un problème, son environnement social et géographique, impossible de s’approcher d’une quelconque vérité. C’est la raison pour laquelle le datajournalisme ne s’oppose nullement au “journalisme de terrain”, il le complète.
La structuration d’une réalité en un modèle abstrait permet de comparer entre elles des situations forcément différentes parce que séparées dans le temps ou dans l’espace. En d’autres termes, la structuration de l’information permet de mesurer la réalité et de comprendre son évolution. L’alternative (mesurer sans structurer les informations) se heurte aux limites biologiques des humains, qui, outre les limites de leur sens, sont sujets à de nombreux biais dans leur interprétation de la réalité. Un seul exemple: Les juges, dont le métier consister à mesurer la gravité d’un fait, sont beaucoup plus cléments après avoir mangé que lorsqu’ils ont faim. Leur sens de la mesure d’un délit dépend plus de leur appétit que des faits reprochés au prévenu5. Tout est dit6.
Les tentatives de mesure de la réalité ont débuté à peu de choses près avec l’invention de l’écriture. Le premier recensement, par exemple, a probablement eu lieu il y a 3 600 ans, à Athènes7. Mais ce n’est pas avant le milieu du 18e siècle que des mesures systématiques se mettent en place8. Le point de départ de la statistique peut être placé au premier recensement moderne, en Suède, en 1749. Le terme de “statistique” commence à être utilisé dans son sens actuel à la fin du 18e siècle.
La production de données structurées s’intensifie avec la révolution industrielle, au milieu du 19e siècle. Des formats spécifiques de communication des connaissances fondées sur ces données apparaissent au même moment, c’est la visualisation de données. Partout où des données sont produites, les intellectuels de l’époque s’en emparent pour les représenter sous forme de graphiques.
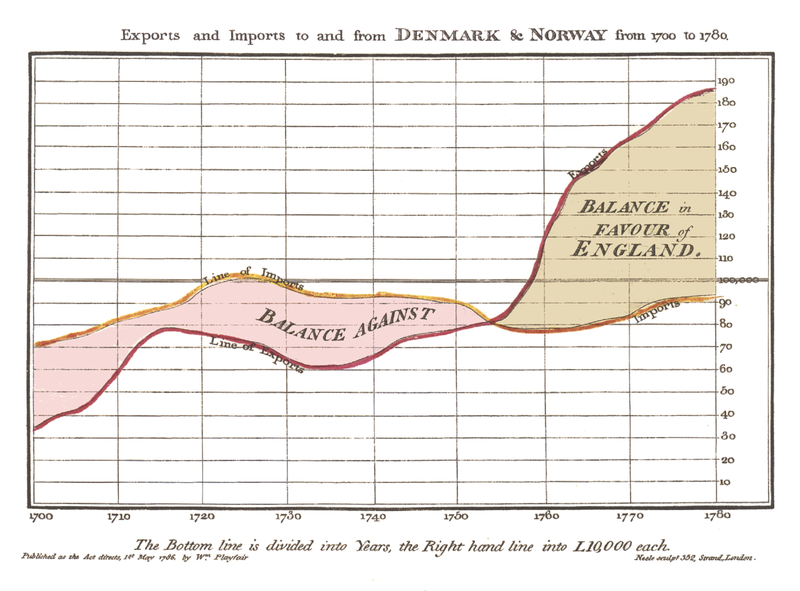 L’une des premières visualisations de données, par William Playfair en 1821.
L’une des premières visualisations de données, par William Playfair en 1821.
Au 19e siècle, la visualisation de données n’était pas réservée à une élite. Au contraire, elles étaient utilisées dans le but de communiquer une information9. William Playfair a utilisé ses visualisations pour promouvoir les baisses d’impôts. Florence Nightingale, une nurse de l’armée britannique lors de la guerre de Crimée, a visualisé les morts au combat par rapports aux morts de maladies infectieuses. Ses visualisations sont connues pour avoir convaincus les décideurs britanniques de la nécessité de moderniser les hôpitaux du pays10.
A mesure que le niveau d’éducation de la population générale augmente, les analyses et visualisations de données dépassent les intellectuels et atteignent le grand public. Dès 1849, des journaux à grand tirage comme le New-York Tribune (à l’époque le plus important de New-York) publient des visualisations de données11. Au 20e siècle, la visualisation de données est utilisée pour communiquer des messages aux masses, comme en atteste son utilisation par sur les affiches du Parti Communiste, parti de masse s’il en est, en France ou en URSS.
 Visualisation de données de l’inflation par le PCF en 1947.
Visualisation de données de l’inflation par le PCF en 1947.
L’utilisation de données structurées dans le débat public ne se limite pas à la visualisation. Au début du 20e siècle, entre 1900 et 1914, la première grande campagne d’activisme moderne se fonde, elle aussi, sur des analyses de données. En 1904, le journaliste britannique Edmund Morel publie Le règne du roi Léopold en Afrique, dans lequel il dénonce l’esclavage à grande échelle pratiqué pour le roi des Belges de l’époque, Léopold 1er, au Congo12. Sa découverte et son argumentation se fonde exclusivement sur l’analyse de la comptabilité de la colonie belge – Morel n’a jamais mis les pieds en Afrique. La campagne utilise ces preuves mais ne les visualise pas ; les éléments visuels utilisés sont des photos prises par Alice Seeley Harris, une missionnaire sur place13.
On le voit, la collecte et la visualisation de données n’a absolument pas attendu internet pour se développer. Depuis le milieu du 19e siècle, les données ont joué un rôle dans la communication d’informations. Pourtant, jusqu’au début des années 2010, les données structurées sont utilisées par divers métiers pour informer sans devenir un champ en soi. Il faut attendre l’émergence de la “science des données” (data science) en général et du journalisme de données dans le domaine de l’information pour que le travail réalisé avec des données structurées soit considéré comme un ensemble cohérent et non plus une collection de compétences éparses. On verra dans un instant pourquoi.
Le CAR, ancêtre du datajournalisme
L’application des méthodes quantitatives des sciences sociales américaines au journalisme marque un premier tournant, dans les années 1960, avec l’apparition du journalisme assisté par ordinateur. Même s’il se fonde sur la puissance de calcul nouvellement offerte par l’informatique, ce tournant est surtout méthodologique. Philip Meyer en est le pionnier. En 1967, Meyer travaille au Detroit Free Press lorsque des émeutes raciales embrasent la ville. Les éditorialistes sont alors prompts à attribuer la motivation des émeutier à leur manque d’éducation. Plutôt que de ce contenter de ces lieux communs, Meyer crée un sondage qui mesure le taux de participation aux émeutes en fonction du niveau d’étude. Après analyse par ordinateur, une nouveauté à l’époque, il montre que les personnes ayant fait des études ont participé aux émeutes dans les mêmes proportions que les autres. La cause de la colère n’était donc pas le manque d’éducation14. Cette enquête, qui utilise les méthodes des sciences sociales et la puissance de calcul des ordinateurs, marque le point de départ du journalisme assisté par ordinateur ou computer assisted reporting (CAR). Meyer a ensuite, en 1970, théorisé sa méthode dans un ouvrage de référence, Precision Journalism15.
Le journalisme assisté par ordinateur se développe aux États-Unis entre 1970 et 2010: La discipline est enseignée dans certaines écoles de journalisme, une conférence professionnelle est créée en 1989 et plusieurs rédactions créent des équipes spécialisées. Plusieurs enquêtes “assistées par ordinateur” reçoivent le prestigieux prix Pulitzer. En 1989, des journalistes de l’Atlanta Journal-Constitution montrent que les banques de la ville prête cinq fois moins dans les quartiers noirs que dans les quartiers blancs à revenus équivalent16. En 1993, Stephen Doig, du Miami Herald, compare les forces des vents de l’ouragan Andrew de 1992 avec l’âge des bâtiments détruits et montre qu’à force de vent égale, certains bâtiments ont beaucoup moins bien résisté que d’autres. En d’autres termes, que les ravages de l’ouragan étaient surtout dus à un problème dans l’approbation des permis de construire17. Cela lui vaut également un prix Pulitzer. En 2001, le Boston Globe enquête sur les prêtres pédophiles de la région ; les tableurs utilisés par ses journalistes ont été popularisés dans le film Spotlight en 2015.
Même s’il est reconnu par la profession, ce journalisme assisté par ordinateur ne change pas les modes de travail des rédactions américaines. Il permet de faire du journalisme d’investigation plus efficacement, mais son impact ne va pas plus loin.
L’émergence du datajournalisme
Le datajournalisme en tant que discipline apparaît véritablement en juin 2010. Des prémisses étaient visible quelques mois auparavant. Le Guardian a ouvert un Datablog en 2009, et je me présentais déjà en tant que datajournaliste à cette époque18, mais le terme n’était pas très usité. Surtout, l’équipe Rob Curley - Adrian Holovaty, premier véritable exemple du genre (j’y reviens dans un instant), ne s’est jamais appelé “datajournaliste”.
En juin 2010, Wikileaks publie les Afghan War Diaries, des extraits de documents internes aux armées de l’OTAN en Afghanistan. Une partie de la base de données source est mise en ligne, au format SQL. Le Guardian, le New-York Times et le Spiegel ont accès aux données en avance, mais les autres rédactions doivent se contenter de la base de données. C’est la première fois qu’un événement d’actualité ne peut être exploré qu’avec les compétences du datajournalisme. Le European Journalism Center, une organisation non-gouvernementale néerlandaise, se charge dans les semaines qui suivent de rassembler les personnes possédant ces compétences, en août 2010, lors de la Data-driven Journalism Roundtable d’Amsterdam, puis via un site internet, datadrivenjournalism.net.
Les compétences en question ne se limitent pas à celles du journalisme assisté par ordinateur. Les équipes qui ont travaillé sur les Afghan War Diaries devaient analyser les données, mais également les visualiser et les publier, là où le journalisme assisté par ordinateur s’arrêtait à l’analyse. En plus de compétences en logiciels de tableur et en statistiques, les équipes de datajournalisme doivent pouvoir visualiser les données et les communiquer sur des écrans, ce qui implique le développement d’applications interactives. Le datajournalisme, c’est en fait la mise en commun des compétences du développement web (créer des contenus et les publier sur internet) et du journalisme (vérifier des informations, trouver un angle et le raconter). Comme l’a dit Alan McLean, du New-York Times, en 2010, il suffit de faire en sorte que les développeurs et les journalistes travaillent côte-à-côte pour que les compétences se mélangent.
 Les slides d’Alan McLean (à l’époque au New-York Times) lors de la conférence d’Amsterdam, en 2010.
Les slides d’Alan McLean (à l’époque au New-York Times) lors de la conférence d’Amsterdam, en 2010.
Si le terme est apparu en 2010, les interactions entre développeurs web et journalistes ont commencé au milieu des années 2000, dès que la technologie a rendu possible le fait qu’une personne ou une petite équipe puisse gérer l’ensemble de la chaîne de production, de l’acquisition des données jusqu’à leur analyse, leur visualisation et leur publication. Le meilleur exemple d’une telle équipe est celle mise en place par Rob Curley (un journaliste) au Lawrence Journal-World, un journal local au Kansas, parmi laquelle on trouve Adrian Holovaty (un développeur)19. Bien qu’ils n’aient travaillé ensemble que quelques années, ils ont posé les bases de ce que la relation développeur-journaliste pouvaient apporter. Ils ont construit eux-mêmes les outils qui leur manquaient pour publier sur le web, sans contracter une société externe ou un vendeur de système de gestion de contenu. Ils ont créé des bases de données sur les sujets les plus importants pour leur audience (notamment le sport étudiant), afin de couvrir le mieux possible les événements locaux. Ils sont sortis complètement du carcan de l’article pour structurer le plus possible l’information et la formatter de la meilleure manière possible pour leur audience. Adrian Holovaty a raconté cette démarche en 2006 dans un court article qui a fait date, A fundamental way newspaper sites need to change.
Informer
Dans le cadre de cet essai, le journalisme est considéré comme étant l’activité de produire ou communiquer des informations vraies. Certaines rédactions publient délibérément des informations fausses. Cette stratégie découle parfois des choix politiques qui guident une rédaction. Russie-1 est l’une des rédactions qui falsifie régulièrement sa couverture de l’actualité pour suivre la politique éditoriale de ses mécènes20, mais on pourrait citer de nombreux autres cas. Publier de fausses informations peut faire partie intégrante du modèle d’affaire d’une rédaction. C’est le cas notamment du Daily Mail21. Enfin, une rédaction peut choisir d’omettre délibérément de mentionner un fait véritable. C’est le cas par exemple du Daily Telegraph, qui a censuré des articles mentionnant la banque HSBC afin de la conserver parmi ses clients22.
On peut utiliser des données structurées pour publier des informations fausses. On peut réutiliser sans les vérifier des informations fournies par une source peu fiable soit par conviction (réutilisation de données que l’on sait fausses), par incompétence (non-connaissance du manque de la fiabilité de la source) ou par choix (absence de processus de vérification de l’information). Certains y voient une faiblesse inhérente au datajournalisme. Cet argument oublie la nécessité, pour qualifier une information de “journalisme”, qu’elle soit vraie. Comme je l’ai montré plus haut, cet argument n’est en rien limité aux données structurées, il peut donc être ignoré.
Un autre argument, avancé parfois de conserve avec le précédent, tient à l’impossibilité de décrire certaines situations par des chiffres. Les statistiques seraient une idéologie et seul le travail de terrain permettrait de comprendre véritablement la réalité23. Outre que, comme je l’ai dit plus haut, les données structurées seules ne peuvent expliquer quoi que ce soit, ceux qui voient dans les chiffres une idéologie se bornent à utiliser un biais cognitif bien connu, celui de l’heuristique de disponibilité. Cette règle de psychologie affirme que les humains prennent plus volontiers les informations qu’ils ont en leur possession pour établir un jugement, plutôt que des informations nouvelles. C’est la raison pour laquelle nous pouvons avoir plus peur des accidents d’avion, dont on entend assez souvent parler, que des accidents automobiles, quand bien même nous savons que les seconds sont beaucoup plus fréquents que les premiers. Il est facile pour un orateur de trouver un seul exemple bien connu de son auditoire pour contrer une analyse statistique rigoureuse portant sur des milliers de cas inconnus24.
Informer, cela signifie aider son audience à donner du sens à son environnement et aux événements qui la touchent. La publication de chiffres sans élément de contextualisation, par exemple, ne saurait être considéré comme de l’information.
La chaîne de valeur de l’information
Trois étapes sont nécessaires pour informer avec des données structurées: La collecte, l’analyse et la communication. Il est fréquent de comparer cette chaîne de valeur avec l’industrie minière: les données, lors de leur collecte, seraient du minerai brut, inutilisable sans être raffiné. Le matériau raffiné (des données nettoyées dans un cas, de l’acier, par exemple, dans l’autre) aurait plus de valeur, mais devrait encore être recombiné pour arriver au produit fini (la connaissance - une voiture) qui, lui, a le plus de valeur. Cette métaphore est attirante et répandue (on parle de “datamining” pour parler d’analyse statistique) mais elle a une faille de taille. En faisant des données une matière première comme du minerai, elle suppose que les données existent à l’état brut. Le concept de “donnée brute” est faux et dangereux. Il est faux car toute donnée provient d’une activité humaine. La donnée n’existe pas à l’état naturel, il faut un système humain pour qu’elle apparaisse. Il est dangereux car en faisant de la donnée un phénomène naturel, il incite les professionnels de l’information à ne pas s’interroger sur le mode de collecte des données, dont découle pourtant toutes les analyses possibles.
Collecter
La création de données structurées nécessite de définir un modèle qui simplifie la réalité. C’est là que les définitions sont établies sur ce que l’on mesure et ce que l’on ne mesure pas. Pour les praticiens, l’écueil le plus important à cette étape est de mesurer tout ce qui peut l’être. Or l’économie de la collecte de données est telle que seules les données apportant un bénéfice eut égard de l’objectif poursuivi doivent être prises en compte. La collecte en elle-même peut prendre plusieurs formes.
Structuration manuelle. Cette technique de collecte consiste à créer des données structurées à partir d’éléments non structurés, quels qu’ils soient. Le projet The Migrants’ Files, coordonné par Journalism++, en est un bon exemple25. Une table recense tous les événements lors desquels des hommes, des femmes ou des enfants sont morts en essayant de rejoindre ou de rester en Europe. Chaque ligne de la table représente un événement, défini sous plusieurs dimensions: date, lieu, type (noyade, assassinat etc.), description, nombre de victimes. Les informations proviennent d’articles de presse, de publications sur les réseaux sociaux ou encore d’appels passés directement à diverses organisations. La nature des événements pris en compte rend toute automatisation est impossible26. Les informations publiées sont très peu structurées (les événements varient grandement en qualité) et les articles les mentionnant peuvent être contradictoires (un naufrage peut donner lieu à plusieurs articles étalés dans le temps, qui s’affinent au fur et à mesure que les informations parviennent aux rédactions). Le travail de structuration doit être fait à la main. The Counted27, un projet du Guardian qui mesure les victimes de la police américaine, collecte ses données de la même manière.
Aspiration de données. L’aspiration de données ou “web scraping” consiste à écrire des programmes informatiques qui acquièrent et structurent des informations publiées ailleurs sur internet. L’observatoire des loyers en Europe, Rentswatch (un projet de Journalism++) se nourrit en partie d’informations collectées automatiquement par des scrapers. Cette technique d’acquisition de donnée nécessite des compétences de programmation informatiques, notamment la maîtrise de librairies spécialisées comme BeautifulSoup (Python), Nokogiri (Ruby) ou Selenium (Javascript). Une fois en place, ces scrapers permettent de collecter des données à un coût marginal quasi nul.
Crowdsourcing. Ce mot-valise constitué de “crowd” - la foule - et “outsourcing” - la sous-traitance - désigne la collecte d’information distribuée entre plusieurs utilisateurs. En général, l’organisation qui collecte les données lance un appel à contributions afin que des utilisateurs fournissent volontairement des données en leur possession. Rentswatch, la base de données des loyers précédemment citée, fonctionne en partie grâce aux informations fournies par les utilisateurs. Le Prix de l’Eau, un projet mené en 2011 par OWNI.fr, demandait aux participants de télécharger leur facture d’eau afin de créer une base de données du prix de l’eau en France.
Capteurs. La diminution du coût des composants électronique permet à n’importe quelle organisation de déployer son propre réseau de capteurs. Le Hindustan Times, à Delhi, met en place des capteurs de pollution atmosphérique pour pallier à la piètre qualité des mesures officielle28. Aux États-Unis, la radio WNYC a allié capteurs et crowdsourcing en 2013, en invitant ses auditeurs à construire des thermomètres pour suivre l’arrivée des cigales dans l’état de New-York29.
Cette typologie de la collecte de données structurées n’est en rien spécifique au datajournalisme. De nombreuses institutions et entreprises collectent des données pour mener à bien leurs missions. Elles peuvent ensuite les publier ou, le plus souvent, les transmettre à un agrégateur qui les publie (en France, c’est l’INSEE qui s’en charge).
Cependant, la collecte implique l’existence d’un modèle, qui simplifie, par définition, la réalité. La création de ce modèle défini le sens que l’on pourra extraire des données lors de leur analyse. Utiliser des données collectées par d’autres, c’est se soumettre à leur vision de la réalité. C’est perdre le pouvoir d’abstraire la réalité selon son propre modèle. Les catégories décidées par le collecteur des données fixent la liste les analyses possibles par la suite. Le recensement de la population effectué par l’INSEE, par exemple, ne mesure que certaines des dimensions que l’on pourrait mesurer pour chaque ménage ou chaque individu (la couleur de peau des individus, par exemple, en est soigneusement exclue, ce qui interdit toute mesure de la discrimination ou de la ségrégation raciale). Les méthodes statistiques utilisées pour choisir les échantillons mesurés jouent également beaucoup sur les données finalement disponibles30.
La collecte de données est là où les sens possibles de l’analyse sont décidés. C’est donc nécessairement l’étape la plus importante de la chaîne de valeur de l’information par les données structurées. Toute organisation se donnant pour but d’informer avec des données structurées doit se doter de capacités de collecte de données31.
Analyser
L’analyse consiste à transformer des données - infalsifiables - en faits - falsifiables - et ainsi à produire de la connaissance. La manière la plus efficace d’analyser les données reste de formuler une hypothèse, puis de la tester. Comme l’a dit le datajournaliste Steven Doig, l’auteur de l’enquête sur l’ouragan Andrew, le datajournalisme, c’est faire des sciences sociales au rythme du journalisme (“social science on a deadline”)32.
Le plus souvent, l’analyse s’effectue manuellement, en utilisant des logiciels de tableur. De simples classements ou la création de ratios peuvent déjà indiquer quels sont les éléments d’un jeu de données qui s’éloignent de la moyenne et qui pourraient être le point de départ d’un article. Certaines analyses peuvent être beaucoup plus poussées. Nate Silver, un statisticien, est célèbre pour avoir prédit en 2008 le résultat de l’élection présidentielle américaine pour chacun des 50 états33. Il a ensuite été embauché par le New-York Times (il dirige désormais fivethirtyeight, son propre média de datajournalisme).
Plusieurs équipes s’essayent à l’automatisation de l’analyse. Marple, un produit développé par Journalism++ Stockholm, recherche automatiquement les pics dans les données locales de criminalité en Suède pour trouver des informations qui auraient pu échapper aux journalistes locaux. Narrative Science, une société américaine, commercialise un logiciel qui, à partir des données d’une rencontre sportive, utilise les statistiques historiques des joueurs pour trouver les faits saillants du match. Lors d’un concours contre un journaliste humain, le logiciel a trouvé des angles qui avaient échappé au journaliste34.
Communiquer
La communication de la connaissance nouvellement créée est le dernier maillon de la chaîne. (On peut également utiliser la visualisation de données lors de l’analyse, mais ce n’est pas l’objet de cet argument). C’est là que la visualisation de données peut jouer un rôle. Les visualisations les plus simples sont les plus efficaces. Edward Tufte, professeur à l’université de Yale, aux Etats-Unis, résume ce concept en parlant de ratio entre la quantité de données affichées et la quantité d’encre nécessaire à leur impression (data-ink ratio). Plus le ratio est élevé (beaucoup de données, peu d’encre), plus le résultat sera efficace35. Les règles de la visualisation efficace des données n’ont pas changées depuis qu’elles ont été établies dans les années 1990 par les infographistes36.
Certains praticiens, aidés en partie par l’accessibilité de nouveaux logiciels (Processing, D3.js), ont développé des visualisations plus complexes. C’est le cas notamment de David McCandless, auteur de l’ouvrage Datavision. La transmission du message passe souvent au second plan de ces types de visualisation, au profit de l’esthétique ou de l’émerveillement recherché. Dès lors, on ne peut plus parler d’information, mais d’art visuel.
Il n’existe malheureusement pas d’étude systématique sur la lisibilité et compréhensibilité des différents types de visualisation de données. Quelques études montrent cependant que les visualisations en 2 dimensions sont mieux retenues que celles en 3 dimensions37 ou que les présentations en barres empilées ou en graphiques circulaires sont moins bien comprises que les tableaux ou les présentations en icônes (voir l’illustration ci-dessous)38.
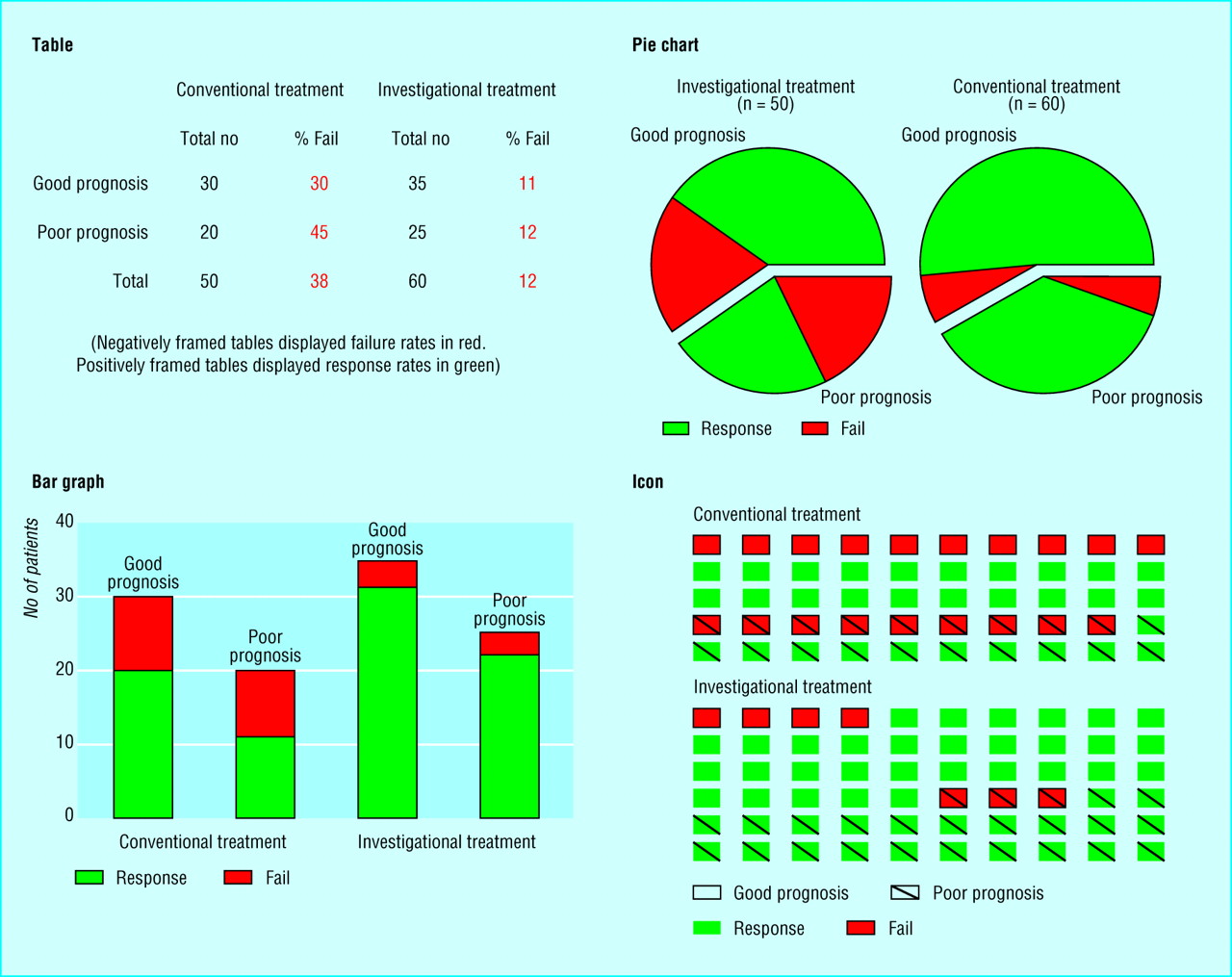 Lors de l’expérience de Elting et al., des médecins devaient prendre des décisions en se fondant sur ces visualisations. 82% des médecins ont pris la bonne décision avec la visualisation en icônes (en bas à droite), 68% avec les tableaux, 56% avec les graphiques circulaires et 43% avec les barres empilées.
Lors de l’expérience de Elting et al., des médecins devaient prendre des décisions en se fondant sur ces visualisations. 82% des médecins ont pris la bonne décision avec la visualisation en icônes (en bas à droite), 68% avec les tableaux, 56% avec les graphiques circulaires et 43% avec les barres empilées.
La visualisation n’est qu’un mode de communication parmi d’autres. Certaines équipes de datajournalisme ne disposent pas de graphistes. Celle du Times de Londres, par exemple, est de celles-là. Elle se voit comme un fournisseur de contenus pour les journalistes traditionnels, qui, eux, sauront communiquer l’information efficacement.
Les organisations produisant de l’information avec des données structurées peuvent se placer à divers niveau de cette chaîne. Des entreprises comme Opta, dans le sport ou Wüest & Partners dans l’immobilier collectent des quantités massives de données qui sont ensuite vendues et parfois utilisées pour informer. Les think-tanks et quelques journalistes utilisent des données collectées par d’autres pour mener à bien des analyses. Les infographistes et certaines agences spécialisées dans la visualisation de données se concentrent sur la communication.
Même si une entreprise peut se positionner à différents niveaux de la chaîne de création de valeur, le rôle crucial (et fondamentalement différent du minerai) de la collecte de données fait que seule l’intégration verticale permet de maîtriser l’information communiquée.
Le rôle sociétal du datajournalisme
La nouveauté du datajournalisme repose sur le fait qu’une organisation ou un individu peut, avec de très faibles ressources, aller d’un bout à l’autre de la chaîne de création de valeur. C’est la raison pour laquelle le datajournalisme peut se définir comme l’action de mesurer ce qui ne l’est pas encore et qui devrait l’être, tout comme le journalisme traditionnel peut se définir comme l’action de donner la parole aux sans-voix. Le fait de pouvoir, pour toute personne, mesurer un phénomène de manière rigoureuse, est très nouveau. Il permet de concurrencer les mesureurs officiels qui, jusqu’à présent, avaient le monopole de la mesure de la réalité.
Un phénomène non mesuré se limite à une suite d’anecdotes. Il est impossible de savoir si le phénomène augmente ou diminue en fréquence ou en intensité. Il est impossible de savoir si l’action des pouvoirs publics ou des acteurs privés influence la réalité d’une manière ou d’une autre. L’administration peut tout à fait décider d’arrêter la mesure d’un phénomène. C’est ce qu’a décidé, par exemple, le gouvernement britannique, qui ne mesurera plus la pauvreté infantile suite aux résultats catastrophiques des politiques menées39.
L’administration peut également décider de na pas mesurer un phénomène, quand bien même elle y est légalement obligée. C’est le cas par exemple des données sur la mortalité des réfugiés qui se rendent en Europe. Bien qu’obligée par le Parlement Européen de réduire la mortalité (et, partant, de la mesurer)40, la Commission Européenne n’a jamais pris la peine de compter le nombre de réfugiés mourant en venant en Europe.
L’administration peut enfin décider de sciemment mal mesurer un phénomène. Prenons l’inflation. La théorie économique veut que, lorsque plus de monnaie entre en circulation dans une économie donnée, les prix augmentent41. Certains observateurs pointent du doigt l’incohérence entre l’absence d’inflation et l’augmentation des liquidités en circulation dans le système économique européen depuis le début du programme d’assouplissement quantitatif (quantitative easing)42. Cette dissonance n’est pas liée à la théorie économique, qui cesserait brutalement de fonctionner. Elle est liée à la mesure de l’inflation, qui se concentre sur des dépenses de l’Européen moyen. Or, l’inflation actuelle concerne exclusivement les Européens les plus riches. Les prix de l’art, du vin d’investissement, de l’immobilier et des produits financiers augmentent tous, parfois dans des proportions considérables (le prix du vin d’investissement a augmenté de 8% par an depuis 2007, par exemple43). En ignorant le découplage de l’économie, partagée entre stagnation et récession de la majorité et dynamisme d’une minorité de super-riches, les instituts de mesure empêchent d’analyser correctement les conséquences de l’assouplissement quantitatif.
On le voit, l’administration n’est pas toujours la mieux placée pour mesurer les conséquences de ses propres politiques. L’indépendance des instituts de mesure, si elle est parfois inscrite dans la loi44 peut être remise en cause de multiples manière. La loi peut par exemple spécifier la méthodologie d’une mesure. C’est la cas pour l’indice de revalorisation des pensions, en France, qui est supposé refléter l’inflation mais ne peut - légalement - prendre en compte le tabac. Cela évite au gouvernement de revaloriser les pensions alors qu’il augmente considérablement le prix des cigarettes. Par ailleurs, la dépendence financière des instituts de mesure vis-à-vis du gouvernement réduit grandement leur capacité à établir indépendamment ses mesures45.
Le datajournalisme peut, en collectant, analysant et communiquant des données structurées, apporter un contrepoids aux mesures officielles. The Migrants’ Files, précédemment évoqué, a servi de point de départ au travail de collecte de données de l’Organisation Internationale des Migrations, un organisme financé par les états. The Counted, le projet du Guardian de mesure des victimes de la police, a poussé le FBI à modifier la manière dont il compte le nombre de victimes. The Woman Tax, un projet de Journalism++ visant à mesurer les différences de prix des produits genrés, a été repris par les rapporteurs du gouvernement sur le sujet46.
Les équipes de datajournalisme
Pour faire du datajournalisme, une organisation doit pouvoir collecter, analyser et communiquer des données structurées. Les compétences nécessaires sont multiples: développement informatique, statistiques, expertise thématique, design graphique. Parce que les projets à réaliser peuvent varier en taille et en compétences nécessaires, parce qu’il faut souvent collaborer avec d’autres domaines (universités, administration, entreprises) ou d’autres rédactions47, il est impossible de travailler en flux, où les tâches à réaliser sont identiques d’une période sur l’autre. Le travail “en mode projet” est indispensable, mais il ne s’intègre pas facilement aux processus de création de l’information des rédactions traditionnelles. Pour travailler en mode projet, la compétence de gestion de projet devient la plus centrale. Or cette compétence est souvent absente des rédactions traditionnelles et les écoles de journalisme ne l’intègrent pas à leur cursus.
On l’a vu, la compétence-clé du datajournalisme est le développement informatique. La culture de l’univers de la programmation est sensiblement différente de celle du journalisme traditionnel. Là où le journaliste idéalise le travail solitaire de longue haleine, les développeurs privilégient la collaboration. Là où le journaliste agit dans le secret, les développeurs privilégient l’ouverture de leur travail (l’open source). Là où le journaliste publie une fois pour toutes, les développeurs enrichissent leur travail des retours des utilisateurs ou de leurs pairs. Cette différence culturelle, qui s’ajoute à une différence de processus de création de l’information, freine considérablement l’adoption du datajournalisme dans les rédactions.
L’entre-soi des journalistes, réel ou ressenti, nuit également à l’ouverture des rédactions à d’autres compétences. L’incapacité de certains journalistes issus d’écoles “reconnues par la profession” à accepter que l’on puisse faire du journalisme en ayant étudié la programmation informatique les empêche de développer des liens professionnels forts avec les développeurs. Il n’est pas rare qu’un datajournaliste, une fois embauché, se retrouve dans un rôle de support technique auprès de ses collègues.
Certaines rédactions, après avoir embauché des datajournalistes, leur ont attribué le titre de “documentaliste”. D’autres ont mis en place des équipes constituées de développeurs, graphistes et journalistes/chefs de projets, mais n’ont pas institutionnalisé cette organisation (en ne nommant pas de responsable d’équipe, notamment), rendant la structure instable et inefficace. Ces tâtonnements ont empêché ces rédactions de capitaliser sur les expériences menées. Parallèlement, plusieurs écoles de journalisme ont ajouté des cours de datajournalisme à leur cursus dès le début des années 2010 mais n’ont pas changé leur méthodes de recrutement (pour former des étudiants issus de filières informatiques et techniques) ni leurs méthodes d’apprentissage, limitant grandement la portée des cours de datajournalisme.
Ces limites sont en partie propres à la France. En Europe, des cursus spécialisés dans le datajournalisme existent. Unidad Editorial, à Madrid, propose l’un des meilleurs master dans le domaine. Les universités de Birmingham (Royaume-Uni) et Tilburg (Pays-Bas) ont également des cursus spécialisés.
Surtout, peu d’organismes de presse français forment de véritables entreprises à but lucratif. La plupart n’existent que pour satisfaire les désirs politiques d’oligarques. Xavier Niel, patron de Free et propriétaire du Monde, du Nouvel Observateur et investisseur dans de nombreux autres médias, résumait sa stratégie d’investissement en ces termes: “Quand les journalistes m’emmerdent, je prends une participation dans leur canard et ensuite ils me foutent la paix."48 Face à de tels propriétaires, les rédactions françaises n’ont aucun intérêt à prendre des risques pour faire évoluer leurs techniques de production. Ailleurs en Europe, des entreprises médiatiques dont la mission est de créer de la richesse en produisant de l’information ont su intégrer le datajournalisme à leurs rédactions. Le groupe allemand Funke, par exemple, a établi une équipe de datajournalisme au Berliner Morgenpost, l’un de ses titres locaux. L’équipe de Berlin est chargée de réaliser des projets de datajournalisme qui sont ensuite adaptés aux autres titres du groupe. En Pologne, le groupe Agora (propriétaire entre autre de Gazeta Wyborzca) a lancé BIQ Data, une section spécialisée (et payante) dans le datajournalisme.
Les épisodes marquants du datajournalisme dans les rédactions, notamment les enquêtes faisant suite à des base de données fournies par des lanceurs d’alertes (Cablegate en 2010, SwissLeaks en 2015 ou les Panama Papers en 2016), font prendre conscience de la nécessité de faire évoluer les processus de création de l’information. Ce fut le cas par exemple au Süddeutsche Zeitung en 2015. Après avoir reçu les documents des Panama Papers, les enquêteurs de la rédactions se sont rendu compte de leur incapacité à traiter efficacement ce type d’information et ont du recruter une datajournaliste.
D’une nouveauté incongrue en 2010, le datajournalisme est devenu une discipline à part entière. Si certaines rédactions, surtout en France, peinent à l’adopter, d’autres le mette à profit pour mener des enquêtes et réaliser des produits attirants pour leur audience. Surtout, les compétences du datajournalisme débordent du théâtre traditionnel de l’information. Des agences, comme Journalism++ ou OpenDataCity, jouent un rôle central en créant des contenus éditoriaux et en formant journalistes et décideurs. Des organismes américains à but non-lucratif, comme le consortium international des journalistes d’investigation (ICIJ) ou le centre d’enquête sur le crime organisé et la corruption (OCCRP), fournissent des compétences manquantes aux rédactions européennes. Enfin, des scientifiques, des associations et divers groupes s’approprient les techniques du datajournalisme et produisent eux-même des données et des analyses49.
La capacité à quiconque de publier est amenée à disparaître à mesure que les plateformes (Facebook, Google) donnent la priorité aux entreprises approuvées et à mesure, surtout, que les entreprises de télécom (Free, SFR) acquièrent des marques de presse et bloquent les contenus en provenance d’autres sources. Mais malgré ce rétrécissement des canaux de diffusion, le datajournalisme pourra continuer à être pratiqué au sein et en dehors des rédactions. En effet, on a vu que la communication ne représentait qu’une partie du travail du datajournalisme - et pas la plus importante. Par ailleurs, le financement du datajournalisme en Europe ne passe que peu par la publicité, si bien que les restrictions de diffusion n’impacteront que faiblement les praticiens.
Notes
1. C’était la position de Guillaume Narvic, un essayiste spécialisé dans l’étude des médias, en 2010, par exemple, exprimé dans cet échange avec Jean-Christophe Féraud.
2. C’était en 2012 la position de Caroline Goulard, fondatrice de la société Dataveyes, exprimé dans Le Data Journalisme pour les nuls
3. C’est la définition de Tanja Aitamurto, chercheur finlandaise spécialiste du sujet, donnée en 2011 dans Trends In Data Journalism.
4. Lire à ce sujet le premier chapitre de Raw Data Is An Oxymoron, Data before the Fact, de Daniel Rosenberg.
5. L’étude concerne 1 112 jugements dans des tribunaux israéliens. Lire Extraneous factors in judicial decisions.
6. Pour une présentation plus détaillée des biais auxquels nous sommes sujets, lire How Information Graphics Reveal Your Brain’s Blind Spots.
7. Voir Cecrops, King of Athens: the First (?) Recorded Population Census in History.
8. La comptabilité moderne, à double entrée, est utilisée depuis le début de la Renaissance. Même si les concepts utilisés peuvent être considérés comme statistiques (simplification de la réalité et création d’abstraction à des fins de comparaison), ces données ne semble pas avoir été utilisées à des fins de création de connaissance avant le 18e siècle.
9. Voir notamment cette sélection des visualisations de données marquantes du 19e siècle.
10. Exemples tirés de la présentation Florence Nightingale’s statistical diagrams.
11. Lire The Above Chart Manifesto de Scott Klein.
12. Le livre est en accès libre sur OpenLibarary.org.
13. L’histoire de cette campagne est brillament racontée dans Les fantômes du roi Léopold, Un holocauste oublié
14. Regarder la vidéo Reading the Riots: how the 1967 Detroit riots were investigated.
15. Lire en ligne l’édition révisée en 1991 The New Precision Journalism.
16. Les articles de l’enquête sont disponibles sur The Color of Money
17. Lire Complete Scans of “What Went Wrong”: The Pulitzer Prize-Winning Special Section of the Miami Herald, December 20, 1992
18. Par exemple ici, dans un de mes premiers articles pour OWNI.fr: Le datajournalisme pour incarner l’histoire.
19. Curley raconte dans Holovaty stepping out on his own sa relation de travail avec Holovaty.
20. Comme lorsque la chaîne affirme que les troupes soviétiques sont intervenues à Prague en 1968 pour protéger le pays d’une invasion des forces de l’OTAN, par exemple. Lire à ce sujet Russian 1968 Prague Spring Invasion Film Angers Czechs, Slovaks
21. Lire notamment à ce sujet My Year Ripping Off the Web With the Daily Mail Online
22. Tel que raconté par Peter Osborne lors de sa démission. Lire Telegraph’s Peter Oborne resigns, saying HSBC coverage a ‘fraud on readers’
23. On en trouve un bon example dans cette tribune de 2006, L’idéologie des chiffres.
24. L’industrie cigarettière a été pionnière dans l’utilisation de cette méthode à grande échelle, comme l’a montré Robert Proctor dans Golden Holocaust, en mettant en avant des fumeurs âgés et bien portants pour décrédibiliser les analyses épidémiologiques.
25. Voir migrantsfiles.com, où les données sources sont disponibles.
26. Le programme de recherche PULS essaye de structurer automatiquement les contenus des articles sur le sujet des migrations mais les données qu’il acquièrent sont tellement pleines de doublons et de contre-sens qu’elles en sont inexploitables.
27. Voir en ligne The Counted.
28. Voir en ligne airquality.hindustantimes.com
29. Voir en ligne le Cicadas Tracker
30. Voir à ce sujet les conséquences de l’échantillonage pratiqué lors du recensement aux Etats-Unis: Should statistical sampling be used in the United States Census?
31. Voir à ce sujet mon essai ‘Free your data’ is over. Now, we need data to be free.
32. “Social science done on deadline”: Research chat with ASU’s Steve Doig on data journalism
33. Voir à ce sujet Nate Silver’s Election Predictions a Win for Big Data, The New York Times
34. We Heard From The Robot, And It Wrote A Better Story About That Perfect Game
35. Voir une illustration de ce concept: Data Looks Better Naked
36. L’ouvrage de référence reste The Wall Street Journal Guide to Information Graphics: The Do’s and Don’ts of Presenting Data, Facts, and Figures, de Dona Wong.
37. Keller, Tanja, and Matthias Grimm. The Impact of Dimensionality and Color Coding of Information Visualizations on Knowledge Acquisition. Lecture Notes in Computer Science Knowledge and Information Visualization (2005): 167-82.
38. Elting, L. S., C. G. Martin, S. B. Cantor, and E. B. Rubenstein. Influence of Data Display Formats on Physician Investigators’ Decisions to Stop Clinical Trials: Prospective Trial with Repeated Measures. Bmj 318.7197 (1999): 1527-531
39. Lire à ce sujet Tory plan to redefine child poverty as figures set to show first rise in decade.
40. C’est l’article 3-b du règlement EUROSUR de 2013.
41. C’est la théorique quantitative de la monnaie, formulée au 16e siècle et toujours acceptée aujourd’hui par la plupart des économistes.
42. Voir par exemple ECB quantitative easing probably won’t bring inflation up to target: economists
43. Voir le Liv-Ex indices
44. C’est la cas pour l’INSEE, comme en dispose l’article 1 de la Loi n° 51-711 du 7 juin 1951 sur l’obligation, la coordination et le secret en matière de statistiques.
45. En 2011, les syndicats de l’INSEE avertissaient par exemple du risque qu’une nouvelle méthode de collecte - moins chère - faisait courir à l’indépendence de l’institut. Lire Insee : l’indépendance de l’indice des prix menacée.
46. Voir L’impossible calcul de la Woman Tax et le rapport au parlement: Etude sur les différences de prix entre certains produits et services selon le genre.
47. La majeure partie des grandes enquêtes de datajournalisme, de Afghan War Diaries aux Panama Papers, ont été réalisés par des équipes transversales, issues de plusieurs rédactions ou entreprise, dans plusieurs pays.
48. Cité dans Un Si Petit Monde. Voir en ligne Comment « Le Monde » fut vendu. Voir aussi Les médias français n’ont pas de stratégie.
49. C’est la cas par exemple des analyses réalisées sur Airbnb par Tom Slee ou de celles réalisées par Nick Diakopoulos sur la responsabilité des algorithmes.